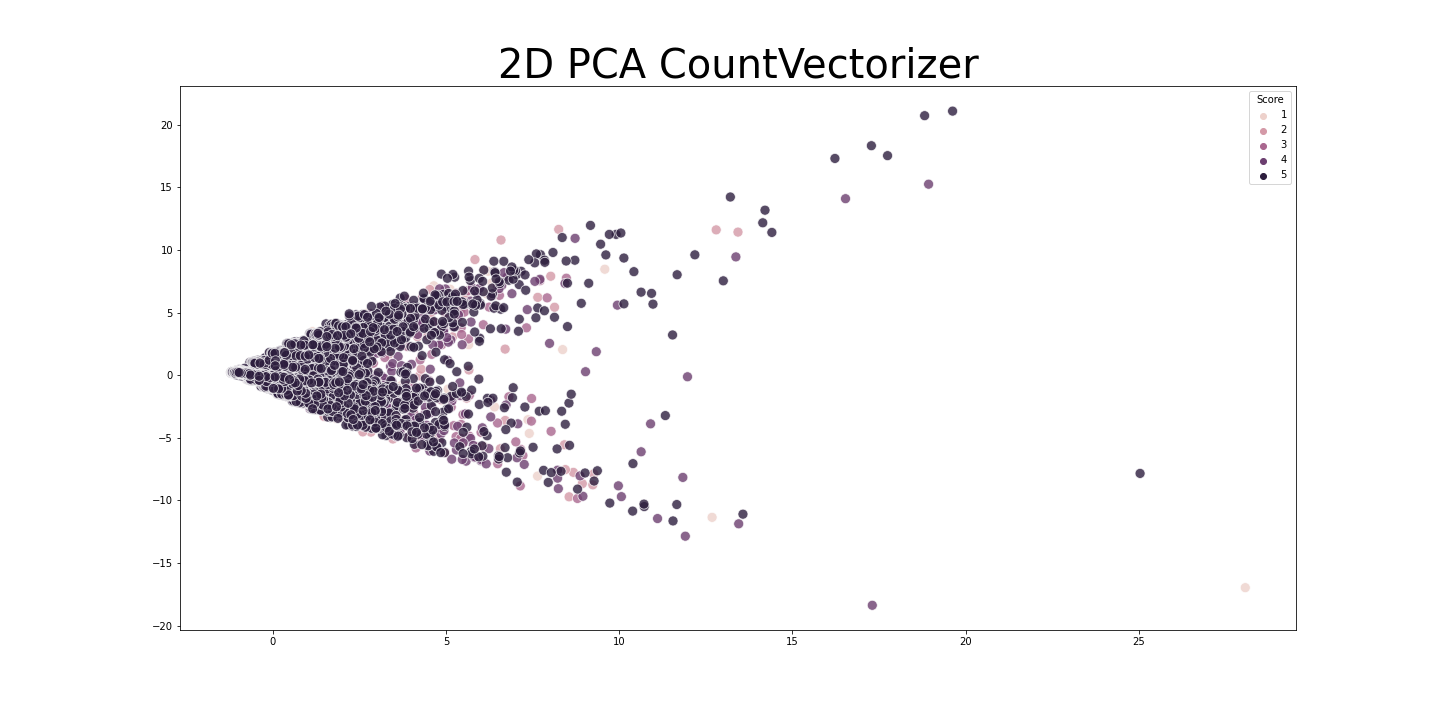
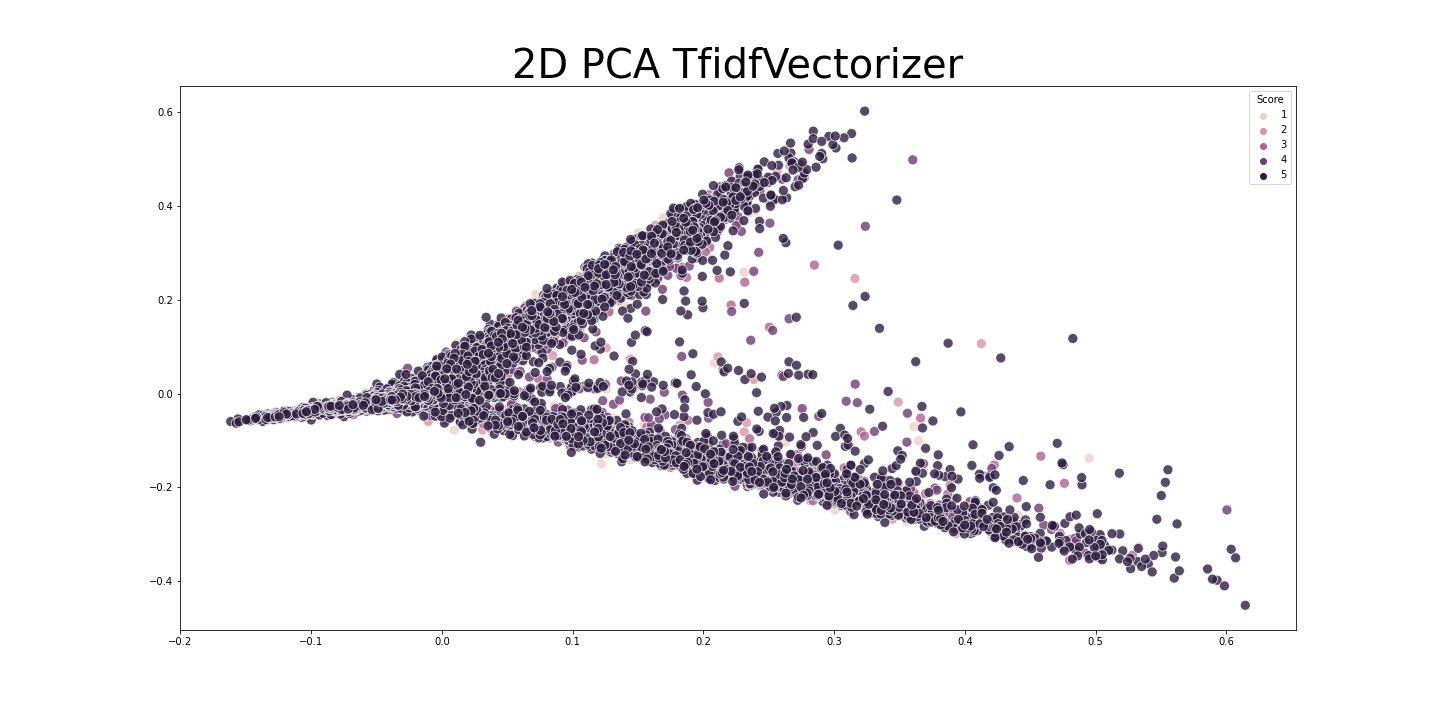
class BiLSTM(nn.Module):
def __init__(self, le, embedding_matrix,max_features, embed_size):
super(BiLSTM, self).__init__()
self.hidden_size = 128
drp = 0.25
n_classes = len(le.classes_)
self.embedding = nn.Embedding(max_features, embed_size)
self.embedding.weight = nn.Parameter(
torch.tensor(embedding_matrix, dtype=torch.float32))
self.embedding.weight.requires_grad = False
self.lstm = nn.LSTM(embed_size, self.hidden_size,
bidirectional=True, batch_first=True)
self.linear = nn.Linear(self.hidden_size*4, 200)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(drp)
self.out = nn.Linear(200, n_classes)
def forward(self, x):
# rint(x.size())
h_embedding = self.embedding(x)
#_embedding = torch.squeeze(torch.unsqueeze(h_embedding, 0))
h_lstm, _ = self.lstm(h_embedding)
avg_pool = torch.mean(h_lstm, 1)
max_pool, _ = torch.max(h_lstm, 1)
conc = torch.cat((avg_pool, max_pool), 1)
conc = self.relu(self.linear(conc))
conc = self.dropout(conc)
out = self.out(conc)
return out
class LstmModelPytorch(BaseEstimator, TransformerMixin):
def __init__(self, max_features, n_epochs, batch_size, maxlen, embed_size, kFolds, debug, X, y):
# Reproducing same results
self.max_features = max_features
self.le = LabelEncoder()
self.tokenizer = Tokenizer(num_words=self.max_features)
self.n_epochs = n_epochs
self.loss_fn = nn.CrossEntropyLoss(reduction='mean')
self.batch_size = batch_size
self.maxlen = maxlen
self.embed_size = embed_size
self.kFolds = kFolds
self.debug = debug
self.X = X
self.y = y
def load_glove(self, word_index, embed_size):
EMBEDDING_FILE = 'glove.6B/glove.6B.50d.txt'
def get_coefs(word, *arr): return word, np.asarray(arr,
dtype='float32')[:300]
embeddings_index = dict(get_coefs(*o.split(" "))
for o in open(EMBEDDING_FILE, encoding="utf8"))
all_embs = np.stack(embeddings_index.values())
emb_mean, emb_std = -0.005838499, 0.48782197
embed_size = all_embs.shape[1]
nb_words = min(self.max_features, len(word_index)+1)
embedding_matrix = np.random.normal(
emb_mean, emb_std, (nb_words, embed_size))
for word, i in word_index.items():
if i >= self.max_features:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
else:
embedding_vector = embeddings_index.get(word.capitalize())
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
return embedding_matrix
def plot_graph(self, epochs, train_loss, val_loss):
fig = plt.figure(figsize=(12, 12))
plt.title("Train/Validation Loss")
plt.plot(list(np.arange(epochs) + 1), train_loss, label='train')
plt.plot(list(np.arange(epochs) + 1), val_loss, label='validation')
plt.xlabel('num_epochs', fontsize=12)
plt.ylabel('loss', fontsize=12)
plt.legend(loc='best')
plt.show()
def fit(self, X, y=None):
xDf = pd.DataFrame(X, columns=[self.X])
xDf[self.y] = y.to_list()
average_trainingLoss = []
average_validationLoss = []
totalFScore = 0
totalAccuracy = 0
totalConfusion_matrix = None
kfold = StratifiedKFold(n_splits=self.kFolds,
shuffle=True)
foldCounter = 0
bestModel = None
bestValidationF1 = 0
# # Do the test train split
# train_X, test_X, train_y, test_y = train_test_split(
# xDf[[self.X]], xDf[self.y], test_size=0.2, random_state=7,stratify=y)
for train_index, test_index in kfold.split(xDf[[self.X]], xDf[self.y]):
foldCounter += 1
train_X, test_X = xDf.iloc[train_index][[
self.X]], xDf.iloc[test_index][[self.X]]
train_y, test_y = xDf.iloc[train_index][self.y], xDf.iloc[test_index][self.y]
self.tokenizer.fit_on_texts(list(train_X[self.X]))
train_X = self.tokenizer.texts_to_sequences(train_X[self.X])
test_X = self.tokenizer.texts_to_sequences(test_X[self.X])
if self.debug:
self.embedding_matrix = np.random.randn(120000, 300)
else:
self.embedding_matrix = self.load_glove(
self.tokenizer.word_index, self.embed_size)
# Pad the sentences
train_X = pad_sequences(train_X, maxlen=self.maxlen)
test_X = pad_sequences(test_X, maxlen=self.maxlen)
train_y = self.le.fit_transform(train_y.values)
test_y = self.le.transform(test_y.values)
# Load train and test in CUDA Memory
x_train = torch.tensor(train_X, dtype=torch.long).cuda()
y_train = torch.tensor(train_y, dtype=torch.long).cuda()
x_cv = torch.tensor(test_X, dtype=torch.long).cuda()
y_cv = torch.tensor(test_y, dtype=torch.long).cuda()
# Create Torch datasets
train = torch.utils.data.TensorDataset(x_train, y_train)
valid = torch.utils.data.TensorDataset(x_cv, y_cv)
self.model = BiLSTM(self.le, self.embedding_matrix,self.max_features,self.embed_size)
self.optimizer = torch.optim.Adam(
filter(lambda p: p.requires_grad, self.model.parameters()), lr=0.001)
self.model.cuda()
# Create Data Loaders
train_loader = torch.utils.data.DataLoader(
train, batch_size=self.batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(
valid, batch_size=self.batch_size, shuffle=False)
train_loss = []
valid_loss = []
for epoch in range(self.n_epochs):
start_time = time.time()
# Set model to train configuration
self.model.train()
avg_loss = 0.
for i, (x_batch, y_batch) in enumerate(train_loader):
# Predict/Forward Pass
y_pred = self.model(x_batch)
# Compute loss
self.loss = self.loss_fn(y_pred, y_batch)
self.optimizer.zero_grad()
self.loss.backward()
self.optimizer.step()
avg_loss += self.loss.item() / len(train_loader)
# Set model to validation configuration -Doesn't get trained here
self.model.eval()
avg_val_loss = 0.
val_preds = np.zeros((len(x_cv), len(self.le.classes_)))
for i, (x_batch, y_batch) in enumerate(valid_loader):
y_pred = self.model(x_batch).detach()
avg_val_loss += self.loss_fn(y_pred,
y_batch).item() / len(valid_loader)
# keep/store predictions
val_preds[i * self.batch_size:(i+1) *
self.batch_size] = F.softmax(y_pred).cpu().numpy()
# Check Accuracy
val_accuracy = sum(val_preds.argmax(
axis=1) == test_y)/len(test_y)
train_loss.append(avg_loss)
valid_loss.append(avg_val_loss)
elapsed_time = time.time() - start_time
print('Epoch {}/{} at {} fold: \t loss={:.4f} \t val_loss={:.4f} \t val_acc={:.4f} \t time={:.2f}s'.format(
epoch + 1, self.n_epochs, foldCounter, avg_loss, avg_val_loss, val_accuracy, elapsed_time))
average_trainingLoss.append(train_loss)
average_validationLoss.append(valid_loss)
y_true = [self.le.classes_[x] for x in test_y]
y_pred = [self.le.classes_[x] for x in val_preds.argmax(axis=1)]
fSc = f1_score(y_true, y_pred, average='weighted')
if fSc > bestValidationF1:
bestValidationF1 = fSc
bestModel = self.model
totalAccuracy += accuracy_score(y_true, y_pred)
totalFScore += fSc
totalConfusion_matrix = totalConfusion_matrix + confusion_matrix(
y_true, y_pred) if totalConfusion_matrix is not None else confusion_matrix(y_true, y_pred)
torch.save(bestModel, 'lstm3CLasses/bilstm_model')
torch.save(self.tokenizer, 'lstm3CLasses/bilstm_model_tokenizer')
torch.save(self.le, 'lstm3CLasses/bilstm_model_labelencoder')
gc.collect()
# Element wise sum the average training and validation loss
average_trainingLoss = np.array(average_trainingLoss).sum(axis=0)
average_validationLoss = np.array(average_validationLoss).sum(axis=0)
self.plot_graph(self.n_epochs, average_trainingLoss,
average_validationLoss)
totalAccuracy = totalAccuracy/self.k_fold
totalFScore = totalFScore/self.k_fold
totalConfusion_matrix = totalConfusion_matrix/self.k_fold
# Save the confusion matrix np save
with open(f"lstm_confusion_matrix.npy", "wb") as of:
np.save(of, totalConfusion_matrix)
# Save the file as json
with open(f"stats.json", 'w') as f:
json.dump({'accuracy': totalAccuracy, 'fScore': totalFScore}, f)
print("## Trained and Tested Model: BiLSTM" +
"\n\t - using lemmitization for tokenization" +
"\n\t - with Glove Embeddings for vectorization" +
f"\n\t - {'without stratification on an unbalanced dataset'if len(X)>2000 else 'on a statified balanced dataset'}")
print("--"*10+"Results" + "--"*10)
print(
# f"- Average Accuracy of BiLSTM across {self.kFolds}-folds = {totalAccuracy/self.kFolds}")
f"- Average Accuracy of BiLSTM across {self.kFolds}-folds = {totalAccuracy}")
print(
f"- Average F1-Score of BiLSTM across {self.kFolds}-folds = {totalFScore}")
# f"- Average F1-Score of BiLSTM across {self.kFolds}-folds = {totalFScore/self.kFolds}")
print(
f"- Average Confustion Matrix of BiLSTM across {self.kFolds}-folds:")
# sns.heatmap(totalConfusion_matrix/self.kFolds, annot=True)
sns.heatmap(totalConfusion_matrix, annot=True)
plt.show()
def predict(self, X):
self.model = torch.load('lstm3CLasses/bilstm_model')
self.tokenizer = torch.load('lstm3CLasses/bilstm_model_tokenizer')
self.le = torch.load('lstm3CLasses/bilstm_model_labelencoder')
# generate list of zeroes only int same as the length of X
y = [1 for _ in range(len(X))]
test_X = self.tokenizer.texts_to_sequences(X[self.X])
test_X = pad_sequences(test_X, maxlen=self.maxlen)
test_y = self.le.transform(y)
x_cv = torch.tensor(test_X, dtype=torch.long).cuda()
y_cv = torch.tensor(test_y, dtype=torch.long).cuda()
valid = torch.utils.data.TensorDataset(x_cv, y_cv)
valid_loader = torch.utils.data.DataLoader(
valid, batch_size=self.batch_size, shuffle=False)
# Set model to validation configuration -Doesn't get trained here
self.model.eval()
val_preds = np.zeros((len(x_cv), len(self.le.classes_)))
for i, (x_batch, y_batch) in enumerate(valid_loader):
y_pred = self.model(x_batch).detach()
# keep/store predictions
val_preds[i * self.batch_size:(i+1) *
self.batch_size] = F.softmax(y_pred).cpu().numpy()
y_new = [self.le.classes_[x] for x in val_preds.argmax(axis=1)]
return y_new
embed_size = 50 # how big is each word vector
# how many unique words to use (i.e num rows in embedding vector)
max_features = 120000
# max number of words in a tweet to use
maxlen = 1000
# maxlen = int(df['cleaned_text'].str.split().str.len().max())
batch_size = 64 # how many samples to process at once
n_epochs = 1 # how many times to iterate over all samples
n_splits = 5 # Number of K-fold Splits
debug = 0
lstmModel = LstmModelPytorch(max_features=max_features,
n_epochs=n_epochs, batch_size=batch_size, maxlen=maxlen, embed_size=embed_size, kFolds=n_splits, debug=debug, X="cleaned_text", y="Score")
df = pd.read_csv('data/train_cleaned_new.csv', encoding='utf-8')
df['cleaned_text'] = df['cleaned_text'].astype(str)
df.loc[:, 'Score'] = df['Score'].map({5: 1, 4: 1, 1: -1, 2: -1, 3: 0})
'''
Uncomment the following line to train the Bi-LSTM model.
'''
# _ = lstmModel.fit(df[["cleaned_text"]], df["Score"])